论文阅读笔记
Center-based 3D Object Detection and Tracking
网络架构
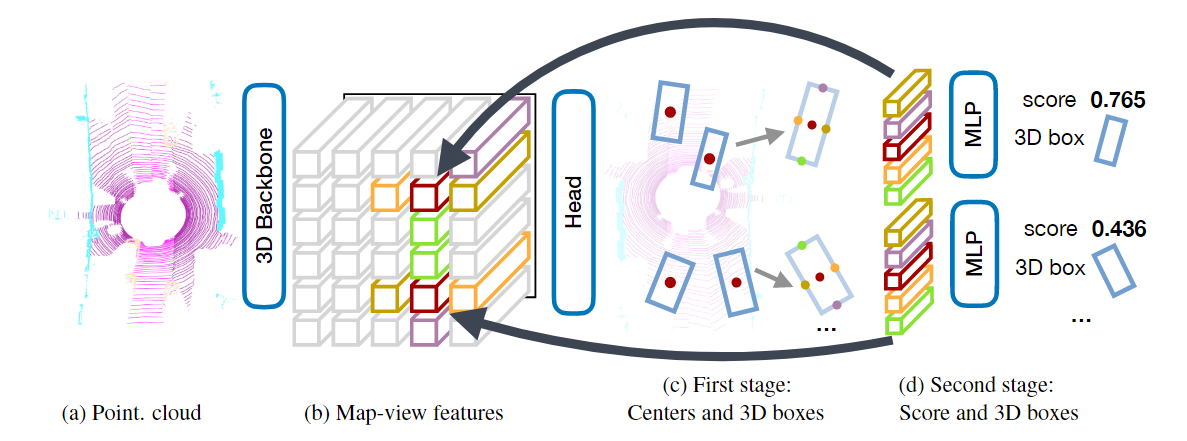
先来看看看这个网络框架和检测流程
第一步,是将点云使用的3d检测头提取特征,这一步主干网络使用诸如VoxelNet或者PointPillars。
原始点云表示为\(N\times4\) ,过特征提取后数据维度就是\(H\times W \times F\) 的Map-View features。
\(H\times W \times
K\) 。这张图k个维度的每一层的局部极大值对应一类检测物体的中心点的位置。训练的时候每一个维度的真值为标注框的
3D
中心点投影到俯视图出形成的二高斯分布在该点处的值。当这个高斯半径小于2时就使用2作为高斯半径避免监督过于稀疏。文中提到这一个中心热图头由3*3
convolutional layer, Batch Normalization, ReLU这三种构成。
第三步,使用回归头:在每个中心点特征处回归子体素位置细化\(o\in\mathbb{R}^2\) ,离地高度\(h_g\) ,3D尺寸\(s\in\mathbb{R}^3\) 和朝向角\((\sin(\alpha),
\cos(\alpha))\) 。子体素位置细化用于减小体素化和主干网络的步长带来的量化误差。以L1回归损失在真实物体中心进行监督。
代码阅读
这里选用Livox Detection V2.0进行阅读,该仓库具有以下特点: - 基于
OpenPCDet框架构建。 - 该检测器的灵感来自于无锚点方法 CenterPoint
模型接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class LD_base (nn.Module): def __init__ (self ): super (LD_base, self).__init__() self.voxel_size = [0.2 , 0.2 , 0.2 ] self.point_cloud_range = [0 , -44.8 , -2 , 224 , 44.8 , 4 ] self.point_to_bev = BoolMap(self.point_cloud_range, voxel_size=self.voxel_size) self.backbone = ResBEVBackboneConcat(30 ) self.head = CenterHead(input_channels=128 , num_class=3 , class_names=['Vehicle' , 'Pedestrian' , 'Cyclist' ], point_cloud_range=self.point_cloud_range, voxel_size=self.voxel_size) for m in self.modules(): if isinstance (m, nn.Conv2d): nn.init.xavier_normal_(m.weight) if m.bias is not None : nn.init.constant_(m.bias, 0 ) def forward (self, batch_dict ): batch_dict = self.point_to_bev(batch_dict) batch_dict = self.backbone(batch_dict) batch_dict = self.head(batch_dict) return batch_dict['final_box_dicts' ]
可以看到模型为三块,体素化BoolMap,
主干网络,检测头。
点云体素化
首先看第一个类BoolMap,
非常简单清晰,将所有的点换算为该点所在的体素的位置,并在bev_img中将该体素置为1。这样bev_img这样一个(B,C,H,W)维的tensor中,值为1表示该处有点,为0表示该处无点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class BoolMap (nn.Module): def __init__ (self, point_cloud_range,voxel_size=[0.2 ,0.2 ,0.2 ], **kwargs ): super ().__init__() self.DX, self.DY, self.DZ = \ voxel_size[0 ], voxel_size[1 ],voxel_size[2 ] self.m_x_min = point_cloud_range[0 ] self.m_x_max = point_cloud_range[3 ] self.m_y_min = point_cloud_range[1 ] self.m_y_max = point_cloud_range[4 ] self.m_z_min = point_cloud_range[2 ] self.m_z_max = point_cloud_range[5 ] self.BEV_W = round ((point_cloud_range[3 ]-point_cloud_range[0 ])/self.DX) self.BEV_H = round ((point_cloud_range[4 ]-point_cloud_range[1 ])/self.DY) self.BEV_C = round ((point_cloud_range[5 ]-point_cloud_range[2 ])/self.DZ) self.num_bev_features = self.BEV_C def forward (self, batch_dict ): pc_lidar = batch_dict['points' ].clone() bev_img = torch.cuda.BoolTensor(batch_dict['batch_size' ],self.BEV_C,self.BEV_H,self.BEV_W).fill_(0 ) pc_lidar[:,1 ]=((pc_lidar[:,1 ]-self.m_x_min)/self.DX) pc_lidar[:,2 ]=((pc_lidar[:,2 ]-self.m_y_min)/self.DY) pc_lidar[:,3 ]=((pc_lidar[:,3 ]-self.m_z_min)/self.DZ) pc_lidar = pc_lidar.trunc().long() bev_img[pc_lidar[:,0 ], pc_lidar[:,3 ], pc_lidar[:,2 ], pc_lidar[:,1 ]] = 1 bev_img = bev_img.float () batch_dict['spatial_features' ] = bev_img return batch_dict
主干网络
主干网络部分选用的是ResNet深度残差网络。从注释看是移植自OpenPCDet。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class ResBEVBackboneConcat (nn.Module): """ Modified from the original implementation of BEV backbone in OpenPCDet. """ def __init__ (self, input_channels, layer_nums=[2 , 2 , 3 , 3 , 2 ], layer_strides=[2 , 2 , 2 , 2 , 2 ], num_filters=[32 , 48 , 64 , 96 , 128 ], upsample_strides=[2 , 4 , 8 , 16 , 32 ] ): super ().__init__() num_levels = len (layer_nums) c_in_list = [input_channels, *num_filters[:-1 ]] self.blocks = nn.ModuleList() self.deblocks = nn.ModuleList() for idx in range (num_levels): cur_layers = [ nn.ZeroPad2d(1 ), nn.Conv2d( c_in_list[idx], num_filters[idx], kernel_size=3 , stride=layer_strides[idx], padding=0 , bias=False ), nn.BatchNorm2d(num_filters[idx], eps=1e-3 , momentum=0.01 ), nn.ReLU() ] for k in range (layer_nums[idx]): cur_layers.extend([BottleNeck(num_filters[idx], num_filters[idx])]) self.blocks.append(nn.Sequential(*cur_layers)) if len (upsample_strides) > 0 : self.deblocks.append(nn.Sequential( nn.UpsamplingBilinear2d(scale_factor=upsample_strides[idx]), )) self.fushion = nn.Sequential( nn.Conv2d(sum (num_filters), 128 , kernel_size=1 , bias=False ), nn.BatchNorm2d(128 ), nn.ReLU(inplace=True ) ) self.attention_w = nn.Sequential( nn.Conv2d(128 , 128 , kernel_size=1 , bias=False ), nn.BatchNorm2d(128 ), ) self.num_bev_features = 128 def forward (self, batch_dict ): spatial_features = batch_dict['spatial_features' ] ups = [] ret_dict = {} x = spatial_features for i in range (len (self.blocks)): x = self.blocks[i](x) stride = int (spatial_features.shape[2 ] / x.shape[2 ]) ret_dict['spatial_features_%dx' % stride] = x if len (self.deblocks) > 0 : ups.append(self.deblocks[i](x)) else : ups.append(x) x = torch.cat(ups, dim=1 ) x = self.fushion(x) w_x = torch.softmax(self.attention_w(x), dim=1 ) x = w_x * x batch_dict['spatial_features_2d' ] = x return batch_dict
检测头
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class CenterHead (nn.Module): ... def forward (self, data_dict ): spatial_features_2d = data_dict['spatial_features_2d' ] x = self.shared_conv(spatial_features_2d) pred_dicts = [] for head in self.heads_list: pred_dicts.append(head(x)) self.forward_ret_dict['pred_dicts' ] = pred_dicts pred_dicts = self.generate_predicted_boxes( data_dict['batch_size' ], pred_dicts ) data_dict['final_box_dicts' ] = pred_dicts return data_dict
其中 1 2 3 4 5 6 7 8 self.shared_conv = nn.Sequential( nn.Conv2d( input_channels, 64 , 3 , stride=1 , padding=1 , bias=True ), nn.BatchNorm2d(64 ), nn.ReLU(), )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class SeparateHead (nn.Module): def __init__ (self, input_channels, sep_head_dict, init_bias=-2.19 , use_bias=False ): super ().__init__() self.sep_head_dict = sep_head_dict for cur_name in self.sep_head_dict: output_channels = self.sep_head_dict[cur_name]['out_channels' ] num_conv = self.sep_head_dict[cur_name]['num_conv' ] fc_list = [] for k in range (num_conv - 1 ): fc_list.append(nn.Sequential( nn.Conv2d(input_channels, input_channels, kernel_size=3 , stride=1 , padding=1 , bias=use_bias), nn.BatchNorm2d(input_channels), nn.ReLU() )) fc_list.append(nn.Conv2d(input_channels, output_channels, kernel_size=3 , stride=1 , padding=1 , bias=True )) fc = nn.Sequential(*fc_list) if 'hm' in cur_name: fc[-1 ].bias.data.fill_(init_bias) else : for m in fc.modules(): if isinstance (m, nn.Conv2d): nn.init.xavier_normal_(m.weight) if hasattr (m, "bias" ) and m.bias is not None : nn.init.constant_(m.bias, 0 ) self.__setattr__(cur_name, fc) def forward (self, x ): ret_dict = {} for cur_name in self.sep_head_dict: ret_dict[cur_name] = self.__getattr__(cur_name)(x) return ret_dict